Address Normalization
This article explains the challenges with address normalization and Socure's approach to achieve a high accuracy.
Address normalization's key challenges
Address normalization plays a crucial role in improving operational efficiency, but performing this task accurately at scale is incredibly difficult due to the inconsistencies and errors in address data.
Some of the key challenges include:
-
Non-standard abbreviations:
- 1011 Farm to Market 1489 vs. 1011 FM 1489
# 2R 110-32 121rst Av vs 110-32 121st Avenue Apt. 2R- Urb. Mountain View C5 H3 vs. Urb. Mountain View Calle 5 H3
- 19 Arboles WI-83 vs 19 Arboles State Road 83
- Inconsistent spellings: Colour vs. Color, Centre vs. Center
-
Inconsistent spellings: Colour vs. Color, Centre vs. Center
-
Missing elements: No ZIP code or state was given.
-
Typographical errors that alter meaning:
- 21533 Via e Palmas vs. 21533 Via De Palmas
- 223 Orchard St #21, but the intended address is 223 Orchard St #12
-
Duplicated streets: Multiple instances of "Main St" in one city.
-
Ambiguous streets: The input address of "123 Division St" is provided and could refer to 123 W Division St or 123 E Division St.
-
Data quality:
- County records indicate a home was rezoned as multi-family splitting a traditional house in 2 units but neither unit are yet recognized by USPS.
- There are over 15 million addresses that exist in county records but are not included in any USPS datasets. If an address is difficult to access due to its remote location or does not generate enough mail volume to justify the costs of providing delivery service, it may not be included in USPS data.
-
Cultural variations and linguistic differences:
- In the UK, the postal code comes before the city name, while in many other countries, the city name comes first.
- In Japan, the address is written differently than in Western countries, with the prefecture name coming first, followed by the city, then the street name and building number.
- In some countries, addresses may include references to landmarks or other non-standard information to help identify the location.
Socure's approach
To overcome these challenges and achieve high accuracy, an address normalization system must be able to interpret the intent behind the input addresses rather than relying on exact text matches.
Socure's address normalization approach uses an ensemble approach of phonetic encoding, metadata extraction, string approximation, lookup tables, advanced pattern recognition, and neural networks to standardize non-standard addresses into a geocode form.
Examples
Our address normalization workflow includes five high-level steps:
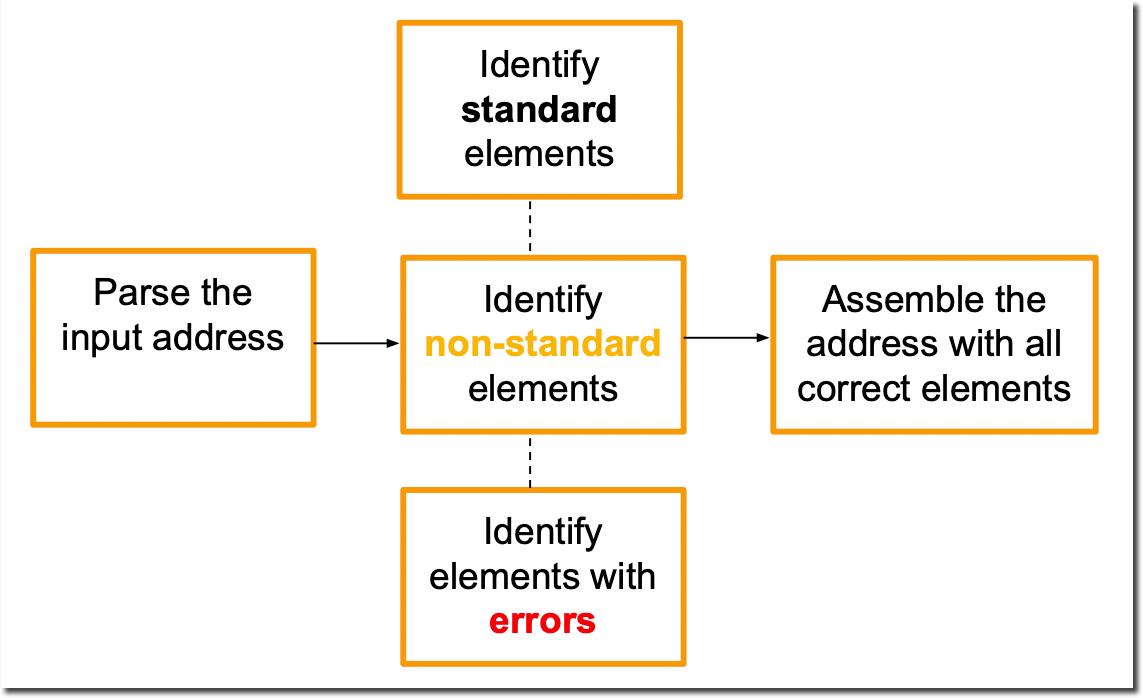
The below examples demonstrate how the workflow is used to formalize the input address:
Example 1:
| Field | Value |
|---|---|
| Input address | 1571 , , north int’; dr, mason icty, iowa, 50404, us |
| Output address | 1571, n international drive, mason city, ia, 50401, us |
| What was corrected |
|
Example 2:
| Field | Value |
|---|---|
| Input address | fl. 21, trevelyan house, 160 totinghigh street, london, sw170ln, uk |
| Output address | flat 21, trevelyan house, 160 tooting high st, london, sw17 0ln, gb |
| What was corrected |
|
Results
The approach applies what we learn to new addresses by developing an understanding of address elements, common errors, abbreviations, and shorthand intuition. The hybrid approach is pre-trained on a large dataset of address pairs, allowing them to learn address normalization rules through self-supervision at scale.
We evaluated our address normalization techniques on 578 million synthetically corrupted addresses from over 2400 sources and their normalized counterparts to achieve the following:
- Precision (correct outputs/all outputs): 99.8%
- Recall (correct outputs/all expected outputs): 97.2%
The high precision and recall demonstrate how hybrid approaches can understand the meaning behind addresses to map them to a normalized form with high accuracy. This allows organizations to improve operations, reduce manual review, and gain more insight from their address data.
Updated 3 months ago